In recent years, words like data and database are commonly used everywhere. It is with data that the world operates every day. Data does not always have to be a complex and confusing entity – even your favorite clothes that you have on your wishlist are pieces of data. So it goes without saying that everywhere around us there is data. But data does not make sense if it is not organized. This is where databases come in.
This article is mainly about what a database is, how databases function, and some common concepts relating to database management. Read ahead and get introduced to the concepts of database, database administration, and the different types of databases in the context of cloud computing.

Alt Text: Graphs on a tablet computer
Source: Pexels
What are Databases?
In the context of websites and applications, a database can be understood as the systematic collection of data in an orderly manner. The most common form in which data is stored is in tables. Data stored in rows and columns is easy to add, edit, delete, manipulate, and find. A database is used by companies, organizations, and businesses to electronically store data in a system to access it easily.
Often database management systems (DBMSs) are shortened to the term database. These systems and applications, apart from storing databases, also let the creators interact with the data dynamically. Through DBMSs, businesses and organizations can easily keep track of their data, however large in number it might be.
Alt Text: Lines of code in a DBMS program
Source: Pexels
Database management programs are often designed to be accessed remotely. The organizations that use these programs control who can access, manage, and edit the data in the database. The majority of database programs use Structured Query Language (SQL) for writing, editing, managing, and querying the data. Some of the most popular open-source DBMS programs include MySQL, PostgreSQL, and Microsoft SQL Server.
Common Types of Databases
In general, databases are of two types – relational databases and non-relational databases. The relational database type takes after the relational model and stores data in tables. On the other hand, the non-relational model opts for non-traditional forms of storing data.
- Relational Database
In the early 1970s, the first ever proposal for a relational model of storing data was proposed. Until then, data was stored in complex structures that could be managed and reviewed only by a select few specialists. Soon after the model was proposed, many developers implemented the idea and arrived at a better solution for storing data in a way that was simple and easy to access. This is how relational databases came into existence.
Relational database management systems (RDBMSs) are simple to understand. The main concept of this type of database is that the data stored in rows and columns have a certain relationship. Every table contains a set of tuples, or rows, and these tuples are defined by a set of attributes, or columns. Establishing a relation among the sets of data is easy in the relational model because that is the core concept of this model.
Let us break it down in even simpler terms. Tuples or rows hold specific categories – each tuple has one association and has attributes like Customer ID, Customer Name, Subject, etc. This way large amounts of data are stored in tables. Now, to access unique pieces of information, a unique ID is introduced – at least one column is assigned as a unique key or a primary key.
Understanding these terms would be easier with an example. Let us assume that a particular database in a company contains information about the employees in a particular department. The attributes for the rows would be something like “Name”, “Start Date”, “Age”, “Position”, “Pay Grade”, and so on. But there has to be a primary key to navigate through the database. This would be the “Employee ID”, which would be a unique identification number for every employee.
If there are two data sets or tables that need to be associated with one another, a foreign key is introduced. The foreign key is the primary key of one table copied into another table under the same or a different name. Let us take the example of employee information and now consider another table that has data regarding different clients and projects. Now in the second table, the Employee ID would be present, indicating the employee who is dealing with a particular. This unique key makes it easy for those who access the database to relate to both databases.
Relational databases boast a wide range of benefits, the most important one of them being data consistency. It is easy to maintain the consistency of data among a wide range of applications and databases in a relational model as different databases are easily linked and connected. Since it is a model based on logic and simplicity, even today many organizations opt to use this type of database for storing their data.
Most relational databases use Structured Query Language (SQL) which is used for adding, editing, fleeting, sorting, and retrieving data from a database.
- Non-Relational Database
While relational database is a term that refers to databases that follow the relational model of storing data, the same cannot be said for non-relational databases. At best, this term can be understood as an umbrella term that encompasses different types of databases that do not follow the traditional, relational method.
Also popularly known as NoSQL, non-relational databases are databases that do not use SQL to add, store, manage, and retrieve data. This model of database started emerging in the late 1990s as a replacement for relational models. This was because there were different types of data that the traditional model cannot accommodate. While relational databases are perfect for organized, structured sets of data, they do not do well with unstructured data. This led to the rise of NoSQL databases.
There are a variety of non-relational database types that are commonly used. Some of them include key-value databases, columnar databases, and document-oriented bases.
- Key-Value Databases
Also known as key-value stores, these databases store data in a string of arrays. Each item or piece of data has a unique key through which it can be accessed. To put it simply, it is like an array object found in many programming paradigms, but these arrays are managed by a DBMS. The associative array, also known as a hash table contains key-value pairs – one entity of the pair is the unique key and the other is the data stored in the respective position of the array.
What’s great with key-value databases is that anything ranging from simple numbers and strings to complex objects can be saved in these associative arrays. Using a compact and easy indexing method, these databases track and retrieve information. Redis is the most popular open-source key-value database management system.
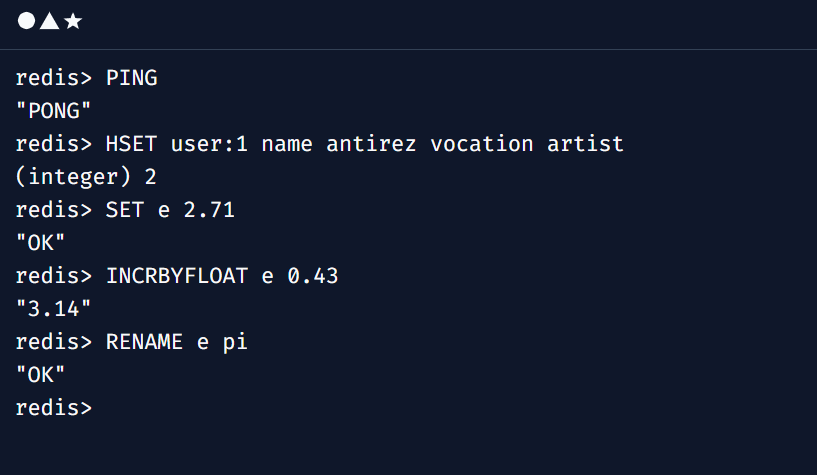
Alt Text: Adding data in Redis
Source: Redis
- Columnar Database
A columnar data-store or database stores data in columns. While this might seem very similar to the traditional relational database model, a columnar database stores data in columns and makes them separate entities instead of grouping them into a table. Columnar databases are popular because they take less run time to return queries. Since only specific columns or column families are searched when a query is issued, any command is executed easily in this type of database. This type of NoSQL database can be very useful when it comes to data warehousing.
- Document-Oriented Database
This database is a type of key-value database – the data is stored in the form of a document, and every document has a unique key that allows access. Document databases often have structures of their own. In a key-value model, the database only handles the entity and not the data within the database. On the other hand, in a document model, the database interacts with the metadata present in the document. This is because the type of data stored in the document provides a certain structure to the database.
In this type of database, data is stored in field-value pairs. The type of data stored can be any type, ranging from simple numbers, and strings, to complex objects. The most common types of formats in which these documents are stored are JSON, BSON, and XML. MongoDB is a popular document-oriented database platform.
Databases as a Part of Applications
While DBMSs are widely popular and useful, they do not find many real-time applications as standalone programs. Businesses link databases with their platforms and applications for an enhanced system where adding, removing, and finding data becomes easier. This is done with the help of several database management tools, and eventually, the database becomes a part of the bigger picture.
Many tech stack models include a DBMS as a part of their setup. This way, it is easy to combine different aspects of a database and an application to arrive at a useful combination. Here are a few examples:
- LAMP stack
Probably the most popular stack model at present, the LAMP stack is made up of 4 layers – Linux (Operating System), Apache (HTTP Server), MySQL (RDBMS), and PHP (programming language). Often, components of this stack are swapped out for other compatible options – for example, often SQLite replaces MySQL. When it comes to cost and efficiency, this stack is considered as one of the best options for web development. Since all of the components of the stack are free and open-source, developers can use these layers effectively and easily.
- MEAN stack
MEAN is an acronym for MongoDB (NoSQL database), Express.js (backend framework), Angular.js (frontend framework), and Node.js (JavaScript for the server side). This is a go-to option for those who prefer the NoSQL model database type, especially document-oriented databases. This stack offers many benefits for developers – not only are the programs open-source and free, but they also use only JavaScript, making it easy for developers to get everything done in the same programming language.
There are two ways in which a database can be made a part of the tech stack. One, all the components of a stack can be a part of the same server. Such a structure is called a monolithic structure – it is a traditional model where all the aspects of an application or software are self-contained. The components of the application are independent and are not involved with other applications.
There is also another way – one can also set up the DBMS on a separate server, known as the remote server. This remote database will operate on a particular port to which the other application servers can connect and access data. This is a better and more effective approach as scaling data from the database is made easier in this method. But there is one major disadvantage to using remote databases – there is a high chance of attacks from unauthorized servers and users. This is why it is important to choose a DBMS that has strong encryption services.

Alt Text: A cursor placed on the option “Security”
Source: Pexels
Encryption is the process where the data inside the database is converted from its original form to ciphertext, a format that can be majorly decoded only by a system. DBMSs enable encryption between the remote database server and the client/application server that accesses the data through activating Transport Layer Security.
Working with Databases
When it comes to working with databases, it is always better to start with popular DBMSs because most of them come with an in-built command line interpreter tool. In simple terms, a command line interpreter is a tool or software that reads the commands that a user enters, interprets them, and executes them. A common example is the mysql command line in the MySQL program. There are also a variety of third-party command-line clients available for DBMSs – Redli for Redis is a good example.
If a command line interface is tough to master in the beginning, graphical database administrator tools can be of great help. Tools like phpMyAdmin (browser-based) and Workbench (remote database) can help beginners to grasp the workings of a DBMS better.
Anyone working with databases should be aware of some of the most common techniques used in operating DBMSs. These techniques will help the user to effectively use the database for storing high volumes of data. Two of the strategies that are often used to effectively store data and improve the performance of the system are replication and sharding.
- Replication – In simple terms, replication can be understood as syncing data across several databases. By having multiple copies of the same data, one can ensure that all the data can be retrieved and accessed even if some servers are down. Database Management Systems usually contain in-built replication features to improve usage.
- Sharding – Sharding refers to the act of splitting up records and spreading them across multiple machines. Sharding involves dividing an already existing table or set of data into multiple shards so it can be distributed among many machines. This technique comes in handy for those who handle large amounts of data across various systems.
Conclusion
Databases and respective management systems are a part of any organization or business. It is with data that the world operates. This article summarizes the basics of databases, their types, and some of the common applications of databases. Databases are also merged with other applications to arrive at better programs that effectively store and process data. Finally, the article also explains what working with databases looks like.